News
Guangdong BAIDU Special Cement Building Materials Co.,Ltd— 新闻中心 —
Qwenlong
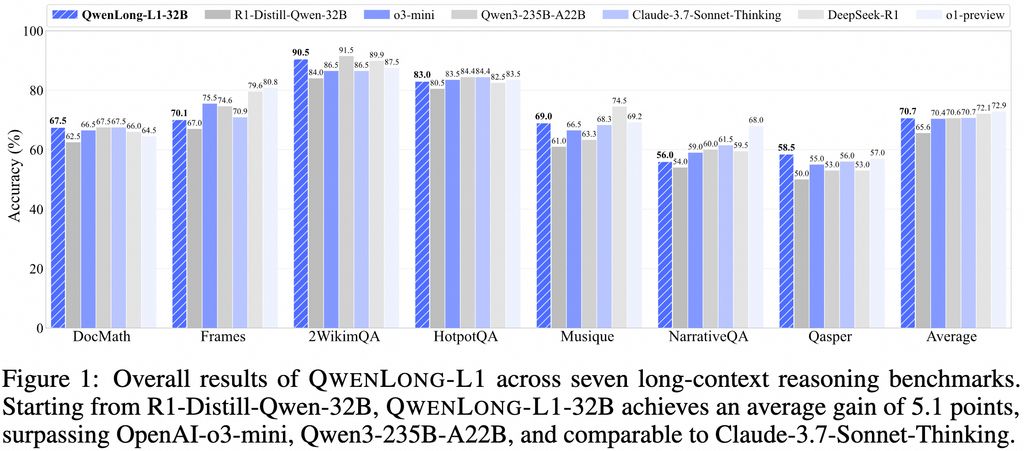 该众议院在5月27日报告说,阿里巴巴Tgyyi Qianwen的QWEN团队昨天(5月26日)发布了Qwenlong-L1-32B模型,这是通过研究增强培训的第一个长篇文本文本推理模型(LRM)。性能不仅仅是七个长文本docqa基准的O3-Mini和Qwen3-235b-a22b等旗舰模型,与Claude-3.7-Connet-Inkinging相当。 Qwenlong-L1-32B模型的最大亮点是支持上下文窗口,最高为131,072个令牌。该模型是基于Qwenlong-L1框架开发的,采用了先进的GRPO(优化相对组和直接(直接对齐政策优化)算法,结合了基于基于和模型的混合奖励功能的基于基于和模型的混合奖励功能,从而显着提高了准确性和有效的方法。伴随通过评估抽样难度激励方法探索的方法。除模型本身外,阿里巴巴还为文本长期推理的问题发布了一套完整的解决方案。该解决方案包括四种主要成分:高性能的Qwenlong-L1-32B模型,专门优化的培训数据集,一种创新的培训方法,培训强化研究和全面的绩效评估系统。参考参考有房子
该众议院在5月27日报告说,阿里巴巴Tgyyi Qianwen的QWEN团队昨天(5月26日)发布了Qwenlong-L1-32B模型,这是通过研究增强培训的第一个长篇文本文本推理模型(LRM)。性能不仅仅是七个长文本docqa基准的O3-Mini和Qwen3-235b-a22b等旗舰模型,与Claude-3.7-Connet-Inkinging相当。 Qwenlong-L1-32B模型的最大亮点是支持上下文窗口,最高为131,072个令牌。该模型是基于Qwenlong-L1框架开发的,采用了先进的GRPO(优化相对组和直接(直接对齐政策优化)算法,结合了基于基于和模型的混合奖励功能的基于基于和模型的混合奖励功能,从而显着提高了准确性和有效的方法。伴随通过评估抽样难度激励方法探索的方法。除模型本身外,阿里巴巴还为文本长期推理的问题发布了一套完整的解决方案。该解决方案包括四种主要成分:高性能的Qwenlong-L1-32B模型,专门优化的培训数据集,一种创新的培训方法,培训强化研究和全面的绩效评估系统。参考参考有房子 - 上一篇:Geely Galaxy促进有限的时间购买:Xingyuan 59,800 yua
- 下一篇:没有了